
new_my_likes
Combine the new and old data:
deduped_my_likes
And, finally, save the updated data by overwriting the old file:
rio::export(deduped_my_likes, 'my_likes.parquet')
Step 4. View and search your data the conventional way
I like to create a version of this data specifically to use in a searchable table. It includes a link at the end of each post’s text to the original post on Bluesky, letting me easily view any images, replies, parents, or threads that aren’t in a post’s plain text. I also remove some columns I don’t need in the table.
my_likes_for_table
mutate(
Post = str_glue("{Post} >>"),
ExternalURL = ifelse(!is.na(ExternalURL), str_glue("{substr(ExternalURL, 1, 25)}..."), "")
) |>
select(Post, Name, CreatedAt, ExternalURL)
Here’s one way to create a searchable HTML table of that data, using the DT package:
DT::datatable(my_likes_for_table, rownames = FALSE, filter="top", escape = FALSE, options = list(pageLength = 25, autoWidth = TRUE, filter = "top", lengthMenu = c(25, 50, 75, 100), searchHighlight = TRUE,
search = list(regex = TRUE)
)
)
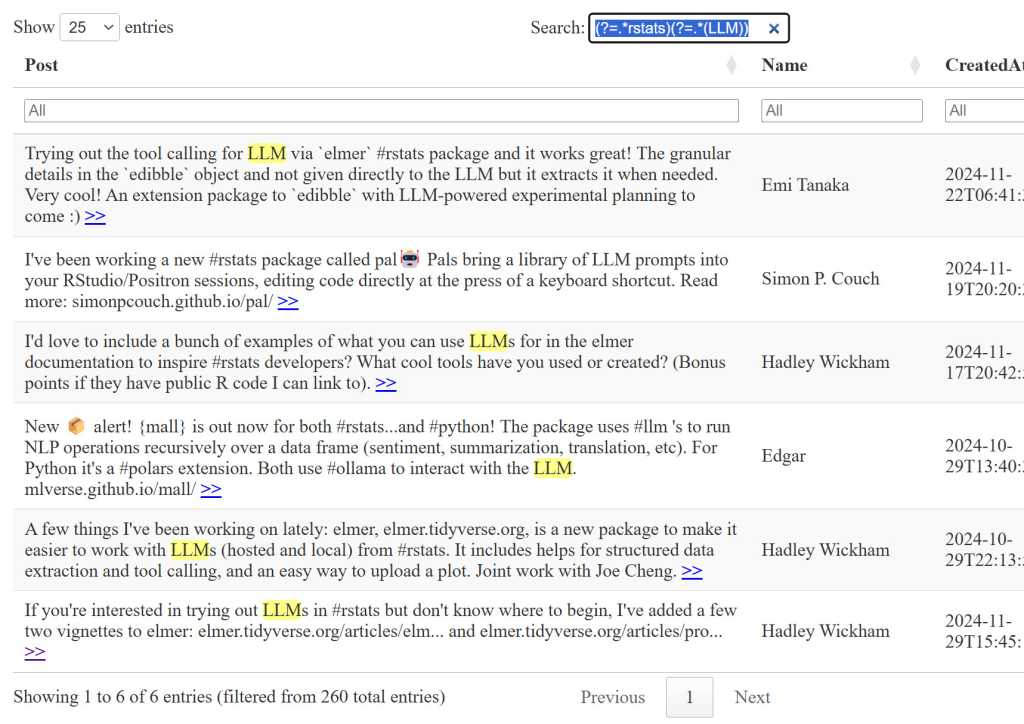
This table has a table-wide search box at the top right and search filters for each column, so I can search for two terms in my table, such as the #rstats hashtag in the main search bar and then any post where the text contains LLM (the table’s search isn’t case sensitive) in the Post column filter bar. Or, because I enabled regular expression searching with the search = list(regex = TRUE) option, I could use a single regexp lookahead pattern (?=.rstats)(?=.(LLM)) in the search box.
IDG
Generative AI chatbots like ChatGPT and Claude can be quite good at writing complex regular expressions. And with matching text highlights turned on in the table, it will be easy for you to see whether the regexp is doing what you want.
Query your Bluesky likes with an LLM
The simplest free way to use generative AI to query these posts is by uploading the data file to a service of your choice. I’ve had good results with Google’s NotebookLM, which is free and shows you the source text for its answers. NotebookLM has a generous file limit of 500,000 words or 200MB per source, and Google says it won’t train its large language models (LLMs) on your data.
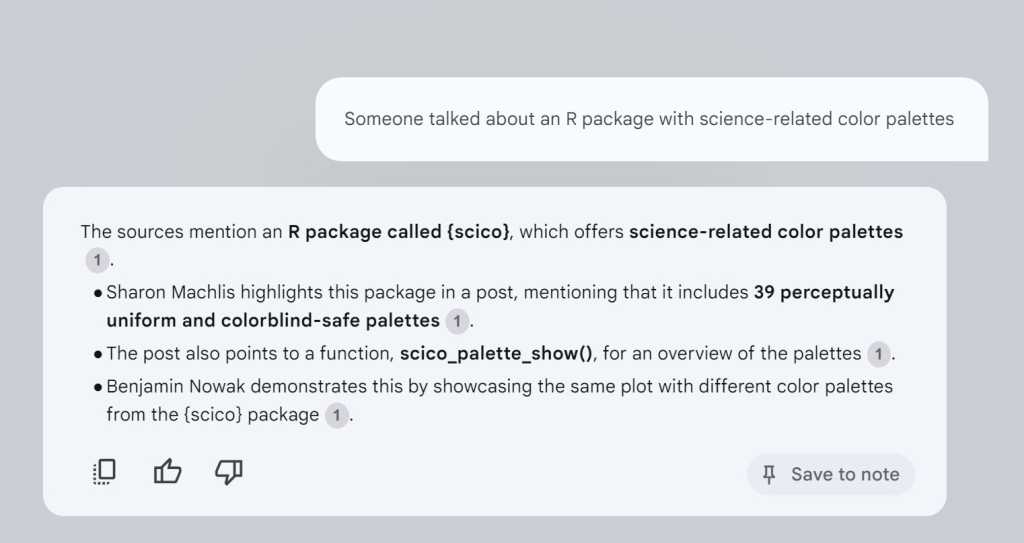
The query “Someone talked about an R package with science-related color palettes” pulled up the exact post I was thinking of — one which I had liked and then re-posted with my own comments. And I didn’t have to give NotebookLLM my own prompts or instructions to tell it that I wanted to 1) use only that document for answers, and 2) see the source text it used to generate its response. All I had to do was ask my question.
IDG
I formatted the data to be a bit more useful and less wasteful by limiting CreatedAt to dates without times, keeping the post URL as a separate column (instead of a clickable link with added HTML), and deleting the external URLs column. I saved that slimmer version as a .txt and not .csv file, since NotebookLM doesn’t handle .csv extentions.
my_likes_for_ai
mutate(CreatedAt = substr(CreatedAt, 1, 10)) |>
select(Post, Name, CreatedAt, URL)
rio::export(my_likes_for_ai, "my_likes_for_ai.txt")
After uploading your likes file to NotebookLM, you can ask questions right away once the file is processed.

IDG
If you really wanted to query the document within R instead of using an external service, one option is the Elmer Assistant, a project on GitHub. It should be fairly straightforward to modify its prompt and source info for your needs. However, I haven’t had great luck running this locally, even though I have a fairly robust Windows PC.
Update your likes by scheduling the script to run automatically
In order to be useful, you’ll need to keep the underlying “posts I’ve liked” data up to date. I run my script manually on my local machine periodically when I’m active on Bluesky, but you can also schedule the script to run automatically every day or once a week. Here are three options:
- Run a script locally. If you’re not too worried about your script always running on an exact schedule, tools such as taskscheduleR for Windows or cronR for Mac or Linux can help you run your R scripts automatically.
- Use GitHub Actions. Johannes Gruber, the author of the atrrr package, describes how he uses free GitHub Actions to run his R Bloggers Bluesky bot. His instructions can be modified for other R scripts.
- Run a script on a cloud server. Or you could use an instance on a public cloud such as Digital Ocean plus a cron job.
You may want a version of your Bluesky likes data that doesn’t include every post you’ve liked. Sometimes you may click like just to acknowledge you saw a post, or to encourage the author that people are reading, or because you found the post amusing but otherwise don’t expect you’ll want to find it again.
However, a caution: It can get onerous to manually mark bookmarks in a spreadsheet if you like a lot of posts, and you need to be committed to keep it up to date. There’s nothing wrong with searching through your entire database of likes instead of curating a subset with “bookmarks.”
That said, here’s a version of the process I’ve been using. For the initial setup, I suggest using an Excel or .csv file.
Step 1. Import your likes into a spreadsheet and add columns
I’ll start by importing the my_likes.parquet file and adding empty Bookmark and Notes columns, and then saving that to a new file.
my_likes
mutate(Notes = as.character(""), .before = 1) |>
mutate(Bookmark = as.character(""), .after = Bookmark)
rio::export(likes_w_bookmarks, "likes_w_bookmarks.xlsx")
After some experimenting, I opted to have a Bookmark column as characters, where I can add just “T” or “F” in a spreadsheet, and not a logical TRUE or FALSE column. With characters, I don’t have to worry whether R’s Boolean fields will translate properly if I decide to use this data outside of R. The Notes column lets me add text to explain why I might want to find something again.
Next is the manual part of the process: marking which likes you want to keep as bookmarks. Opening this in a spreadsheet is convenient because you can click and drag F or T down multiple cells at a time. If you have a lot of likes already, this may be tedious! You could decide to mark them all “F” for now and start bookmarking manually going forward, which may be less onerous.
Save the file manually back to likes_w_bookmarks.xlsx.
Step 2. Keep your spreadsheet in sync with your likes
After that initial setup, you’ll want to keep the spreadsheet in sync with the data as it gets updated. Here’s one way to implement that.
After updating the new deduped_my_likes likes file, create a bookmark check lookup, and then join that with your deduped likes file.
bookmark_check
select(URL, Bookmark, Notes)
my_likes_w_bookmarks
relocate(Bookmark, Notes)
Now you have a file with the new likes data joined with your existing bookmarks data, with entries at the top having no Bookmark or Notes entries yet. Save that to your spreadsheet file.
rio::export(my_likes_w_bookmarks, "likes_w_bookmarks.xlsx")
An alternative to this somewhat manual and intensive process could be using dplyr::filter() on your deduped likes data frame to remove items you know you won’t want again, such as posts mentioning a favorite sports team or posts on certain dates when you know you focused on a topic you don’t need to revisit.
Next steps
Want to search your own posts as well? You can pull them via the Bluesky API in a similar workflow using atrrr’s get_skeets_authored_by() function. Once you start down this road, you’ll see there’s a lot more you can do. And you’ll likely have company among R users.
